
 Source: Shutterstock.
Source: Shutterstock.
This is the 4th article in my series of Text Analytics posts explaining popular approaches to feedback analysis. Earlier, we talked about text categorization, a Machine Learning approach that requires training data. We concluded that it can’t detect emerging themes in people’s feedback and that it’s only as accurate as the supplied training data.
This time, we’ll discuss topic modelling, also a Machine Learning approach, but an unsupervised one, which means that this approach learns from raw text. Sounds exciting, right?
Occasionally, I hear insights professionals refer to any Machine Learning approach as “topic modelling”, but data scientists usually mean a specific algorithm when they say topic modelling. It’s called LDA, an acronym for the tongue-twisting Latent Dirichlet Allocation. It’s an elegant mathematical model of language that captures topics (lists of similar words) and how they span across various texts.
Example of topic modelling in action
Here is an example of applying topic modelling to beer reviews:
- The input are reviews of various beers
- A topic is a collection of similar words like coffee, dark, chocolate, black, espresso
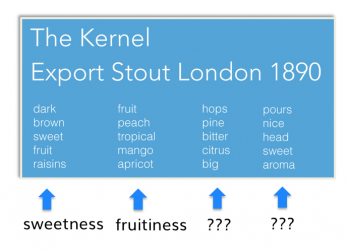
- Each review is assigned a list of topics. In this example, The Kernel Export stout London has 4 topics assigned to it.
 Source: Ben Fields.
Source: Ben Fields.
The topics can also be weighted. For example, a customer comment like “your customer support is awful, please get a phone number”, could have weights and topics as following:
- 40% support, service, staff
- 30% bad, poor, awful
- 28% number, phone, email, call
What’s great about topic modelling
The best thing about topic modelling is that it needs no input other than the raw customer feedback. As mentioned, unlike text categorization, it’s unsupervised. In simple words, the learning happens by observing which words appear alongside other words in which reviews, and capturing this information using probability statistics. If you are into maths, you will love the concept, explained thoroughly in the corresponding Wikipedia article, and if those formulas are a bit too much, I recommend Joyce Xu’s explanation.
There are Text Analytics startups that use topic modelling to provide analysis of feedback and other text datasets. Other companies, like StitchFix for example, use topic modelling to drive product recommendations. They extended traditional topic modelling with a Deep Learning technique called word embeddings. It allows to capture semantics in a more accurate way (more on this in our Part 5).
Why is topic modelling an inadequate technique for feedback analysis
When used for feedback analysis, topic modelling has one main disadvantage:
The meaning of the topics is really difficult to interpret
Each topic does capture some aspect of language, but in a non-transparent algorithmic way, which is different from how people understand language. For instance, how would you interpret the second and the fourth topics for the stout beer in the above example:
 Source: Thematic.
Source: Thematic.
Whereas the first and the second topic can be somehow “named” as sweetness and fruitiness, the other two topics are just a collection of words.
Any data scientist can put together a solution using public libraries that can quickly spit out a somewhat meaningful output. However, turning this output into charts and graphs that can underpin business decisions is hard. Monitoring how a particular topic changes over time to establish whether the actions taken are working is even harder.
To sum up, because topic modelling produces results that are hard to interpret, because it lacks transparency just like text categorization algorithms do, I don’t recommend this approach for analysing feedback. However, I stand by the algorithm as one that can capture language properties fairly well, and one that works really well in other tasks that require Natural Language Understanding.
This post was initially published here.


