

Earlier this year, I collaborated with Jason Baldwin, global head of product management at WPP, on this project to describe five major trends in martech that would shape the decade ahead for agencies and brands. You can download our full paper, including many terrific interviews from WPP executives. I’m republishing it here as a 7-part series. This is part 5.
It’s been said that data is the new oil. A better analogy is that data is the new oil paint.
Oil paints range from $4 to $400 a tube, from common to rare oils and pigments. They’ve got inherent value. But it’s by applying those paints on canvas, in inspired acts of creation, that orders of magnitude greater value can be achieved, transforming matter into masterpieces.

Data by itself has value too, which we can observe through prices in data marketplaces. But it’s by integrating that data into the design and delivery of remarkable customer experiences that marketers create orders of magnitude greater value for their organizations.
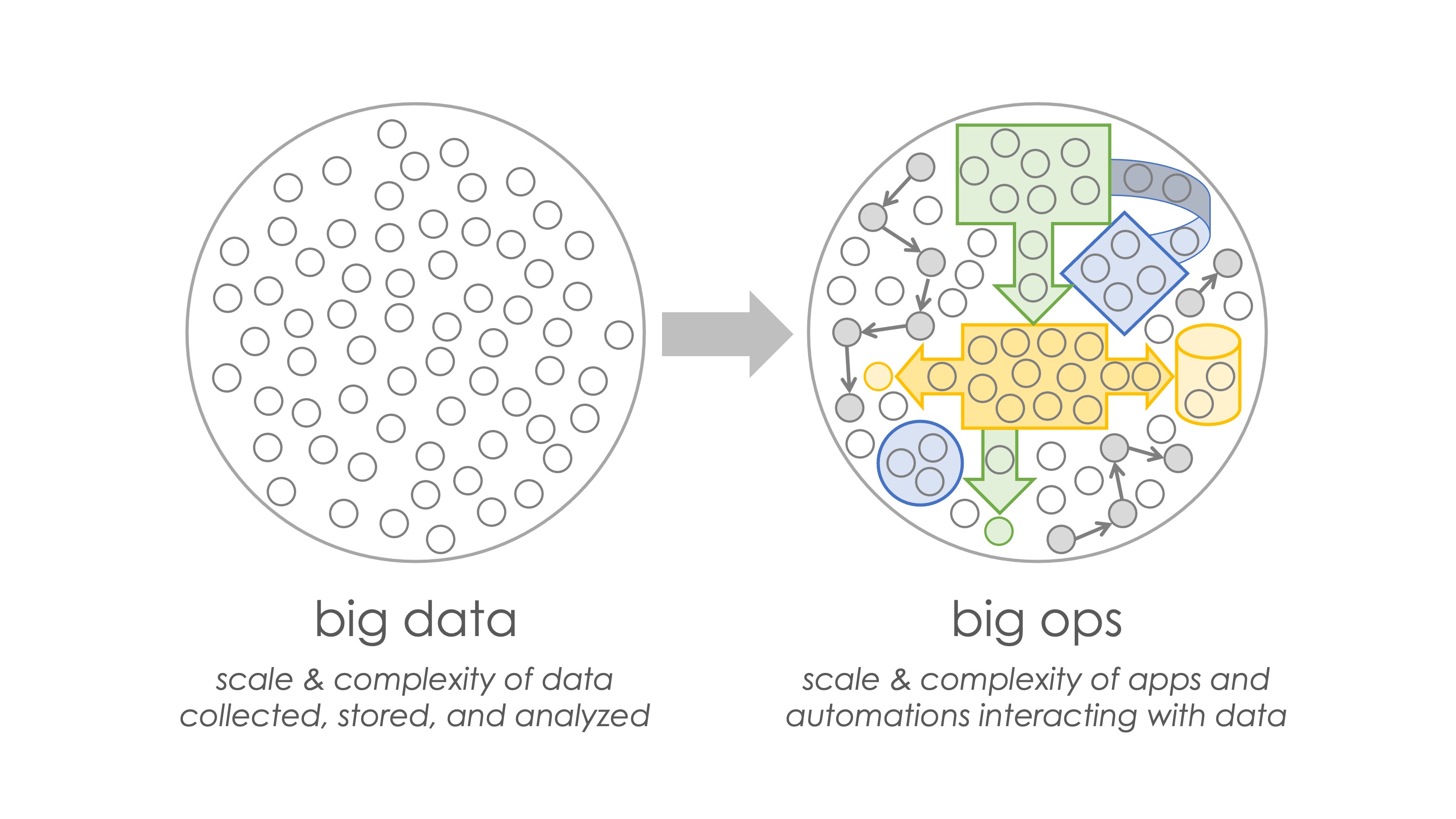
Designing and delivering customer experiences in a digitally-native or digitally-transformed business is a function of an enormous number of apps, automations, bots, decision models, dynamic processes, workflows, skills, people and more — a myriad of human and software “actors” — that must all work in concert together.
Each of these actors operates on data, and their performance is influenced by which data they have access to and its quality. But by operating on data, they’re often altering it too — either updating existing data or contributing new data that they collect, derive, and generate. Because so many software-automated or software-mediated processes are now running in parallel in a digital organization, many with a certain degree of independence, yet all of them interacting with the firm’s collective universe of data, complex interaction effects emerge.
Based on the trends we’ve already examined — The Great App Explosion, which is being fed by more decentralized “no code” citizen creators leveraging platforms and networks — we can expect that complexity to grow exponentially in the decade ahead.
The effectiveness by which companies orchestrate all of this — the massive span of their digital operations — will be a major axis of competitive advantage.
THE DECADE OF BIG OPS
The 2010s were about big data, wrangling the enormous scale and complexity of data flowing into organizations at an accelerating velocity. The 2020s will be more about “big ops” — the orchestration layer on top of that universe of data and its growing scale and complexity.
Just as big data described an exponential growth in the volume, velocity, and variety of data being piped in and out of organizations, big ops describes a similar scaling of the volume, velocity, and variety of automated or software-mediated processes rippling across marketing operations, sales operations, service operations, and overarching revenue operations.
The scale of data in business will continue to grow too, but the mechanics of piping and storing it will be relatively easy and commoditized with cloud platforms. Data competitiveness will be a function of two things:
- The source of your data: its accuracy and freshness; its provenance and legal permissions; and its exclusivity
- How effectively you distill and activate that data in your business operations and customer experiences
It’s the 21st century philosophy riddle: if data is generated, but nobody ever does anything with it, did it even exist? (The answer: we’d be better off if it didn’t. Data that is collected but never used has less than zero value. It’s a liability, with costs of storage and risks of theft.)
Research this year by IDC and Seagate estimated that 44% of all data available to enterprises goes uncaptured, and out of the data that is captured, 43% remains unused. Barely one third of the total is put to work today. The rest is “dark data.” The first mission of big ops is bringing all the relevant data into the light.
DATA INTELLIGENCE & DATA REFLEXES
Capturing available data and putting it to some use is a start, but the “putting it to use” part has a wide range of possibilities that affect its impact. Data grows in value in two dimensions:
- The degree to which it is distilled into information, knowledge, and insight
- The degree to which it is activated in the organization, from reporting to decision-making and, in a big ops environment, driving automated reactions.
The first dimension is your data intelligence. The second is your data reflexes.
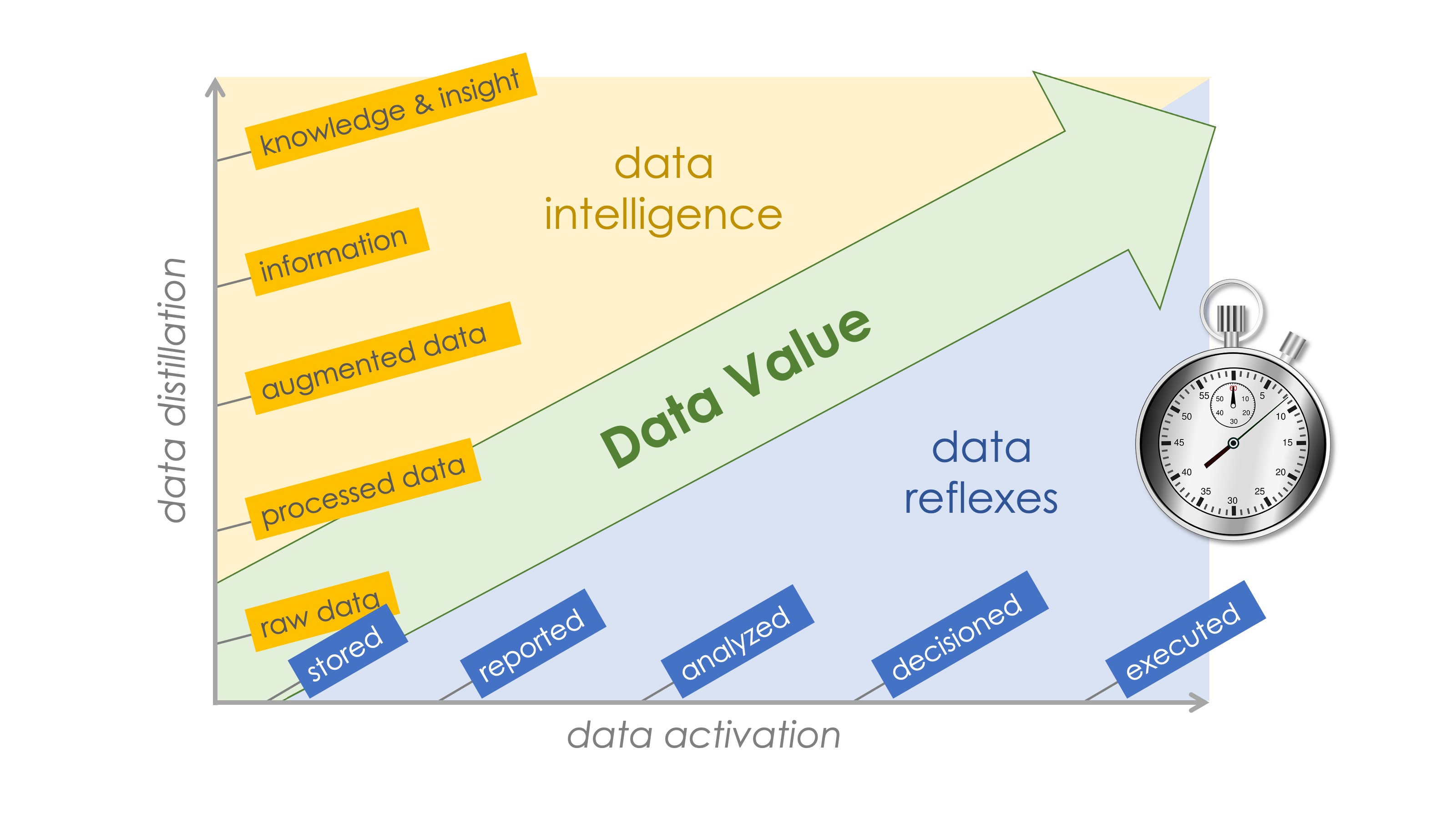
These two dimensions intersect to determine how valuable data ultimately becomes. Data may be distilled to insights, but are they fed into the right decisions at the right time? Data can be merely processed, yet can it immediately trigger a helpful automated response for a customer?
Harnessing data in big ops — developing your data reflexes — relies on data connectivity and data coordination, wrapped by data management and data governance; capabilities that are still in the early stages of maturity for most firms.
Across the myriad of data sources in our organization, are the right data sets connected to an ops process? Can it access relevant data in a timely manner? And with data compliance and data ethics growing in importance, are the “wrong” data sets — those for which a particular ops process should not have access — properly restricted by data governance?
Such data connectivity is the backbone of big ops.
But the real complexity is in data coordination, managing the interdependencies and parallel activity among ops processes and the data they’re working with.
Which ops actors get the first pass at new data? As they validate and process it — format, clean, and augment it — are subsequent actors operating on it properly sequenced? With many actors working with the same data sets, how are conflicting data updates resolved? As other actors continue to enrich and distill that data into higher level insights, are processes upstream iteratively rerun to refresh their models and outputs?
Just as distributed databases are often “eventually consistent” — with caveats and constraints that must be considered in application logic — big ops environments will face a meta version of this challenge as they strive for eventually consistent operations across all internal decisions and customer-facing experiences. Centralized software platforms, as well as blockchain and ledger databases, will help orchestrate this complexity. But governance provided by big ops leadership will be crucial to designing and running this digital operations layer effectively.
These are ops challenges more than data challenges.

COMPETING ON EFFECTIVE DATA USE
As organizations build big ops competencies, they will be in a better position to extract value from additional sources of data that originate beyond the walls of the firm. Marketing organizations will need to invest in the data skills (data literacy) of their people to ensure the skills of the few are second nature to the wider organization over this timeframe, “no code” and platforms strategies will accelerate this understanding. Agencies will continue to plug skill gaps with data literate experts and areas of increasing investment for the industry as a whole.
The decade ahead will see significant growth in data alliances between companies — sharing second-party data — securely brokered by trusted ecosystem data platforms such as Crossbeam and InfoSum.
Data marketplaces for third-party data will also grow. Gartner predicts that by 2022, 35% of large organizations will be either sellers or buyers of data via formal online data marketplaces up from 25% in 2020. From now through to 2025, the number of market providers and data products within data marketplaces and exchanges are expected to grow by 25% a year. Although with increased regulatory pressure, the governance and permission management surrounding the data will be a further complexity for big ops to manage.
An emerging source of data is “zero-party data” that prospects and customers directly manage about themselves and share with companies in a more controlled fashion. Acquiring this data at the right time, for the right purpose, and at the right cost — and adhering to the contracts by which it is provided — will be a key facet of big ops ahead.
Since the same set data will vary significantly in value depending on how effectively a firm is able to operationalize it, there will be increasing opportunities for data arbitrage around these exchanges.
For agencies, there are opportunities to both connect clients with the right second-party and third-party data providers, as an integral element of marketing campaigns and programs, but to also create their own specialized data networks and marketplaces.
Bigs ops will make big data more powerful than ever. However, while that holds tremendous upside for businesses and customers, it will also amplify problems with bias in data sets. Data that misrepresents people, either through its incompleteness or inaccuracy, will ripple across digital operations faster and with more significant consequences.
A crucial element of big ops will be implementing checks and balances to guard against data discrimination and enforcing policies of good data ethics. While technology will help with this mission, leveraging AI to detect operational patterns and anomalies that may indicate data bias or misuse, the weight of good judgment will rest on human shoulders.
Stay tuned for Trend #5: Harmonizing Human + Machine to be published shortly. You can also download the full paper at any time.


