
First, one more reminder: please take our Martech Composability Survey this week. When you see the questions, I think you’ll agree that having a statistically significant dataset for a “no BS” view of this topic would be super valuable for the whole martech community. We’ll share the full results publicly. But we need your participation. Please and thank you!
I’ve been adovcating the benefits of aggregation platforms in martech stacks for a couple of years now. These are platforms that provide cohesion to a diverse set of apps or data sources in your stack. You get both a unified, integrated system — or more accurately, an internal ecosystem — that easily adapts to apps or datasets being added or removed from your stack.
Such aggregation can happen at different layers: data, workflow, user experience, or governance. Some platforms aggregate at multiple layers. But the clearest — and arguably most flexible — examples are those that specialize in aggregating at a single layer.
The quintessential example is a cloud data warehouse, which aggregates at the data layer. You can have many different data sources contributing data to the warehouse. And you can have many different apps pulling data from the warehouse. No matter how many sources and apps you have, the warehouse serves as one common hub for all of them.
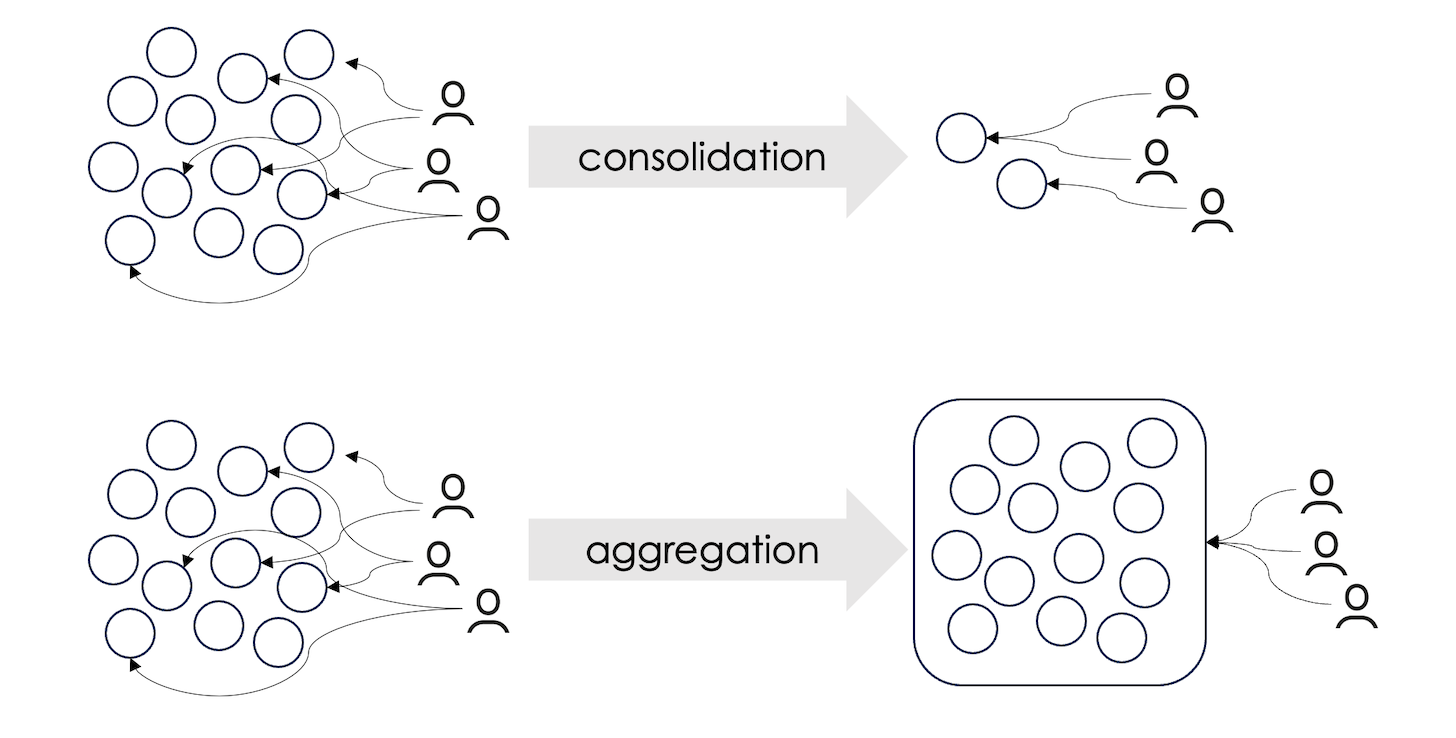
A key characteristic that distinguishes an aggregation platform from other kinds of software: the more things you connect to it, the more value you get from it. An aggregtion platform delivers “network effects” within your stack. (This is in contrast to point-to-point integrations in a stack that become more complicated and fragile as you add more things to your stack.)
Cloud data warehouses have this characteristic: the more things you have pushing and pulling data to and from them, the more value you can derive because they make such a wide span of data accessible to so many applications. (With the caveat that you need to actively manage this so it doesn’t turn into a data swamp.)
This isn’t hypothetical. Cloud data warehouse use is on the rise in marketing. Winterberry Group recently published an excellent research paper, Demystifying the Data Layer: The Transformation of Marketing Data Infrastructure, that sheds light on this shift.
Across the US, UK, and Europe, marketers are increasing — or significantly increasing — investment in their data infrastructure:
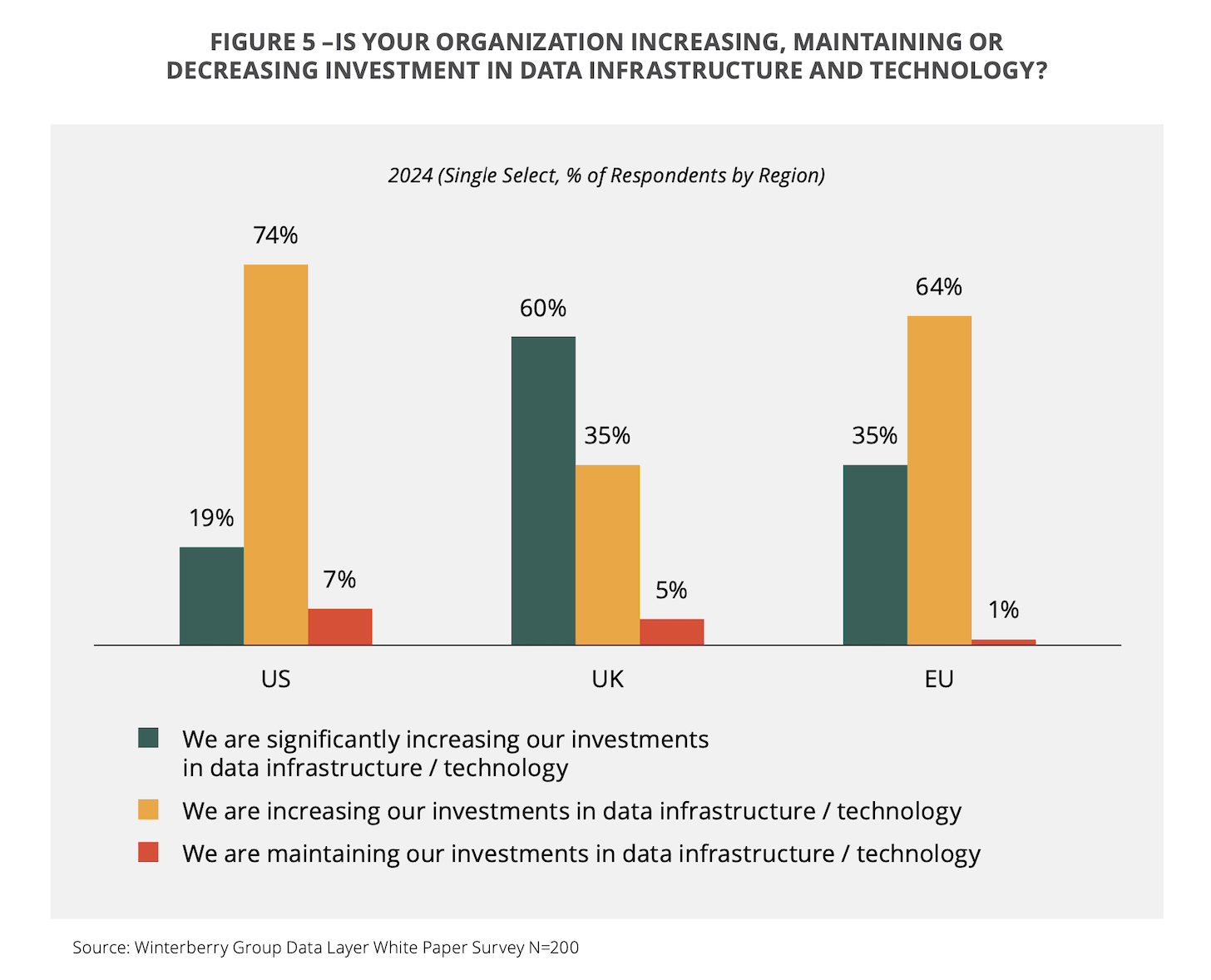
Hey, as the saying goes, “AI strategy is data strategy.” And everybody needs an AI strategy now. So having 93% of US companies, 95% of UK companies, and 99% (!!) of European companies beefing up their data infrastructure to enable AI-powered operations isn’t that surprising.
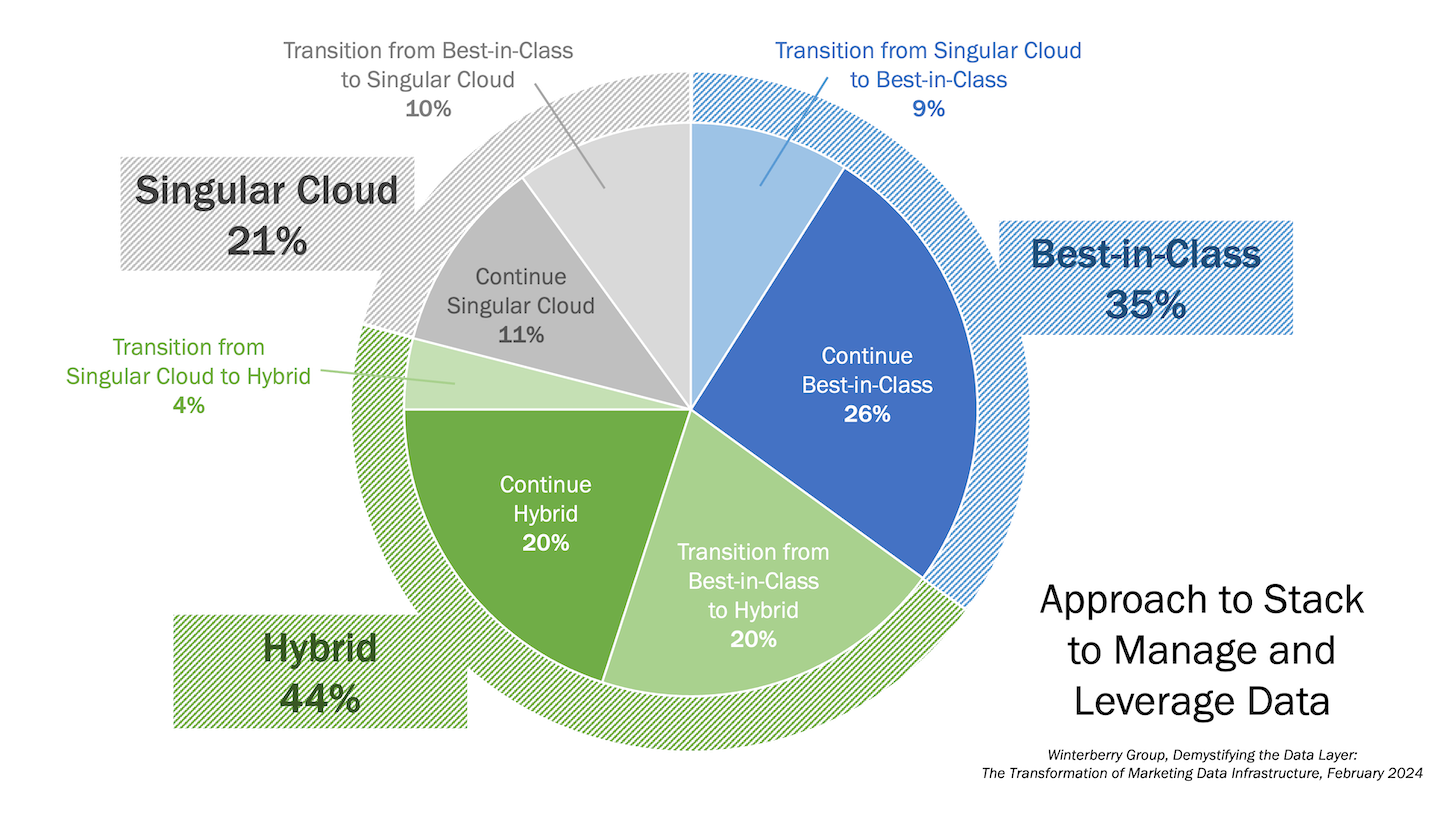
What may be surprising to some — at least to ardent advocates of austere consolidation — is the graph at the top of this article that shows most companies (79%) are not using a “singlular cloud” solution for managing and leveraging this data. Most are either using a best-in-class stack (35%) or a hybrid stack (44%).
Hybrid architectures “[blend] the strengths of centralized platforms with specialized best-in-class solutions.” This sounds to me like an aggregation platform: one central platform, connected to multiple specialized apps. That 44% of marketers are taking this route — more than doubling with those who are transitioning to this model — is a testament to its suitability to our currrent tech and data environment.
There was a related finding in the report that caught my eye:
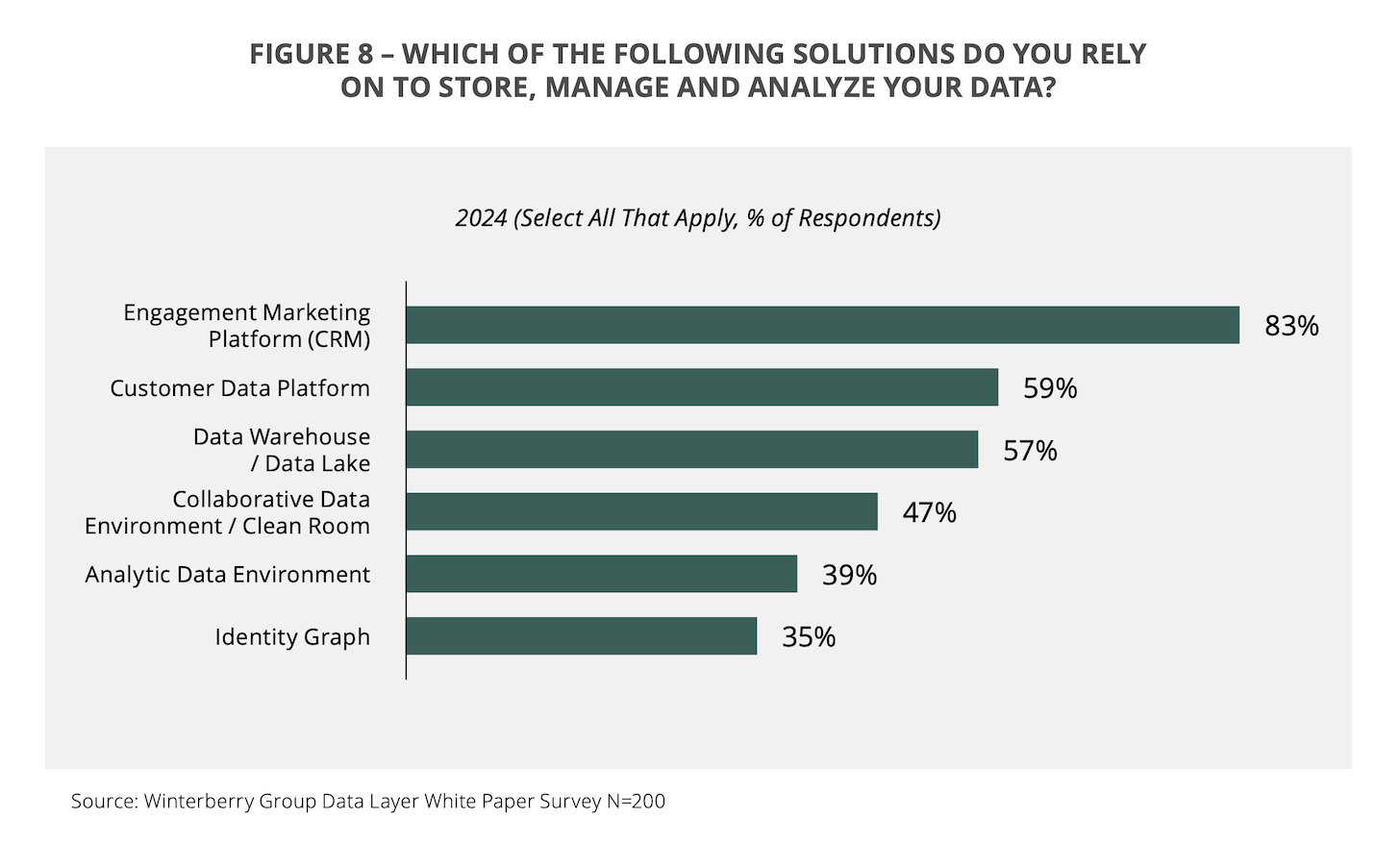
Asking marketers which solutions they use to store, manage, and analyze data, you can see from the percentages that there are obviously multiple solutions working in parallel most people’s stacks.
Almost everyone (83%) uses a CRM. Another 59% use a customer data platform (CDP). And another 57% use a data warehouse or data lake. Even though a case could be made for each of these to be the “system of record” or “source of truth”, you’ve obviously got a lot of stacks out there with two or three of these in them.
While some architectural purists may object, I think this can be a pragmatic design pattern. If these platforms are sharing the same data with each other — which they should, at least to an extent — real-world operations can benefit from having that data locally available in the context of each particular application. It can speed up performance, and it can adapt the “shape” of the data to the functional model of that application.
A CRM empowering salespeople has different uses than a CDP orchestrating a marketing campaign or a data warehouse that’s being mined by an analyst. As long as the common data is synchronized across them, such a “federated” architecture can let each optimize interactions with that data for their users and use cases.
A cloud data warehouse as an aggregation platform can be particularly effective here, serving as the Grand Central station of data integration. Data that is relevant to multiple applications is unified in the warehouse. But the subset of that data used by individual apps may — emphasis on the word may — be federated into other apps when that delivers the greatest operational efficiency.
But what about silos? Surely they’re universally bad?
Well, don’t call me Shirley. Here’s the thing: data is expensive to move, expensive to store, expensive to compute on, and — in the cost of human time and talent — expensive to manage. Granted, with a data warehouse as a data aggregation platform, it is much less expensive than it was before. But the costs are not zero.
So you only want to send data to the warehouse if there are legitimate cases for how that data will be used. There’s a ton of operational data buried within the mechanics of how different apps work that doesn’t have relevance elsewhere in your stack.
What’s important is the option to share data. Any data that an app collects or generates should be able to be piped into a warehouse (or other kind of data aggregation platform), so that you can choose to leverage it elsewhere in your stack when a use case arises. It’s a silo with many doors.
Unified, federated, and even siloed data all have roles in martech stacks.
Last reminder: please take the Martech Composability Survey! Participation in the occasional study like this is my one ask of readers. You’ll be able to see the full results, which I think you and the rest of our community will find interesting and useful. Thank you!


