
Last week, I introduced the notion that businesses can gain deeper customer insights if they connect their disparate data silos. Similar to how oncologists can leverage information from genome sequencing to tailor cancer treatments for a specific patient in order to improve health outcomes, businesses can use all customer data from disparate data silos to personalize interactions with their customers to improve customer loyalty.
Data Integration as your Customer Genome Project
Using the 2×2 graphical approach to understanding data size (i.e., number of customers and number of variables), we can see how the value of your integrated business data is greater than the sum of its parts. Figure 1 illustrates these two components of size by examining four different scenarios of how businesses use their data. In the lower right quadrant, it is business as usual; when departments keep their data siloed, each department only knows a few things about the customers. Analytics is used to build general rules for broad customer segments (e.g., male vs female; age segments).
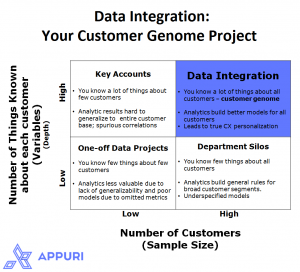
The lower left quadrant represents one-off projects where a sample of customers is used to study a phenomenon. Analytics in these types of projects may be less valuable due to lack of generalizability (to the other customers) and poor models (e.g., underspecified) due to omitted metrics.
Key Account programs are best categorized as projects falling in the upper left quadrant, where you know a lot of things about a few “important” customers (Accounts). In these situations, analytic results of a small set of accounts may be difficult to generalize to the entire customer base.
Integrated data sets (those in the upper right quadrant) allow you to know a lot of things about all your customers. Analytics applied to these types of data help you generate better predictive models because your integrated data contain all the key variables that are useful in predicting your outcome (e.g., user engagement, customer loyalty). Additionally, using these “customer genomic” type data sets to build your predictive models, you are better able to target specific customers with personalized treatment that resonates with them (i.e., segmentation on steroids).
Machine Learning and Predictive Modeling
Once you have integrated all your data silos, the next step is to use predictive modeling to identify the variables that are predictive of your outcome variable, typically customer loyalty. Because these integrated data sets are so large, data scientists are simply unable to quickly sift through the sheer volume of data manually. Instead, to identify key variables and create predictive models, businesses can now rely on the power of machine learning to quickly and accurately uncover the patterns in their data.
Iterative in nature, machine learning algorithms continually learn from data. The more data they ingest, the better they get. Based on math, statistics and probability, algorithms find connections among variables that help optimize important organizational outcomes, in this case, customer loyalty. Coupled with the processing capability of today, these algorithms can provide insight quickly to improve marketing, sales and service functions.
Summary
Your customer insights are limited by the variables used in your modeling and your analysis of those data. Because each data silo contains only a small part of what defines your customers, analyzing silos separately leads to sub-optimal models. Additionally, machine learning allows you to interrogate your data efficiently. By knowing more about your customers (the variables and how they are related to each other), you can build better, more comprehensive, predictive models which ultimately allow you to have a deeper understanding of your customers, providing you with insights about ways to improve the customer experience to increase customer loyalty.
This article originally appeared on Appuri.


