
Brands are using AI to drive hyper-personalization, but can it also help them avoid being hyper creepy?

Source: https://www.adclarity.com/2015/04/digital-marketing-2015-hyper-personalization-display-ads/
Apparently, I have 8 seconds to grab your attention, so here goes. What if I personalized every aspect of this blog for you? That is, I knew so much about you – your reading behavior, the writing style you prefer, subjects you love – took all of it into account, and assembled these words and pictures just for you? Would you find that creepy or cool?
At our conference in Las Vegas recently, I was a guest on Sam Charrington’s, podcast series “This Week In Machine Learning and AI.” In that episode, we discussed a similar hyper-personalization scenario, where an automotive company used intimate knowledge about a consumer and her connected car to custom-tailor each marketing and service treatment[i]. And half-way through (at 23:07), Sam observed that although “consumers appreciate personalized experiences,” it can go too far and “sometimes come across as creepy.”
And suddenly, we both realized something. Customer experience experts haven’t used AI to govern this. In other words, CX pros personalize without recognizing if their personalization levels are approaching creepiness.
Which led to this question: can creepiness be quantified? And if so, with that knowledge, could a company effectively use it? With the right tooling, could they safely test and simulate how far personalization should go, carefully delivering each customer a tailored experience with the right level of relevance and value, without crossing into their creepy space? Simply put, hyper-personalizing without being hyper-personal — the personalization paradox.
You’re marketing is creeping me out
Creepy land is that forbidden zone where consumers call out businesses for using personal data and revealing insights that are a bit too private. And though consumers increasingly want personalized experiences (according to a recent Epsilon study[ii], 90 percent of consumers find it appealing), ironically, they will happily make examples of brands that invade their personal space.
No brand wants a creepy reputation as it implies:
- Stalking, snooping, or spying; collecting personal data and invading privacy
- Revealing something private, no matter how valuable the insight
- Not having customers’ best interests in mind
- Ill-intent, even when there isn’t intention to do harm
With big data galore, a culture of a data sharing, and pressure to mass personalize to remain competitive, you need ways to safely and systematically explore the creepy line’s location without ever crossing it. Understanding what customers expect and why they love a product (or don’t) is crucial to great personalization. Avoiding a creepy moniker means effectively steering clear of areas that are, frankly, none of your business. And if the customer says it’s none of your business, it’s none of your business.
Today, the digital world abounds with copious quantities of demographic, psychographic, and behavioral data. There’s a sea of it, because for decades companies have wired up clients and monitored them like lab rats. And with more IoT tech and data coming every day, firms increasingly misuse it, giving customers more reasons to demand privacy. The problem is the definition of what’s private and sensitive can be different for each person. Hence the dilemma: under personalize and risk being labeled clueless, not cool, and worse miss out on revenue; over personalize and risk breaking trust and doing irreparable damage to your reputation.
Sorry we’re creepy. We apologize for any inconvenience
Customer engagement professionals need new and scalable ways to survey buyers, collect preferences and permissions, sense their intent and moments of need, and personalize appropriately. So, they need ways to test where that creepy boundary is. That line is fluid and ever shifting and finding the right level of personalized insights and recommendations without crossing into risky territory is never without some uncertainty.
Where that line lurks changes with time because initially customers may be leery of something, then later adapt to it. It also changes because privacy legislation changes, individual consumers have distinct levels of sensitivity, and varying levels of awareness. It can even differ by geography. For instance, a 2016 study of 2000 consumers in Europe found that 75 percent were uncomfortable with facial recognition software used to target them with personalized offers (consumers in the US were much less sensitive)[iii]
Data-driven marketers have evolved their practices (Figure 1) using data to acquire more customer knowledge which in turn powers more personalization. Over time, more marketers have evolved their practices, from the general advertising Mad Men approaches of the 1960’s to the super-personalized, AI-Powered approaches possible today. It also highlights how that pushes them closer to the creepy space.
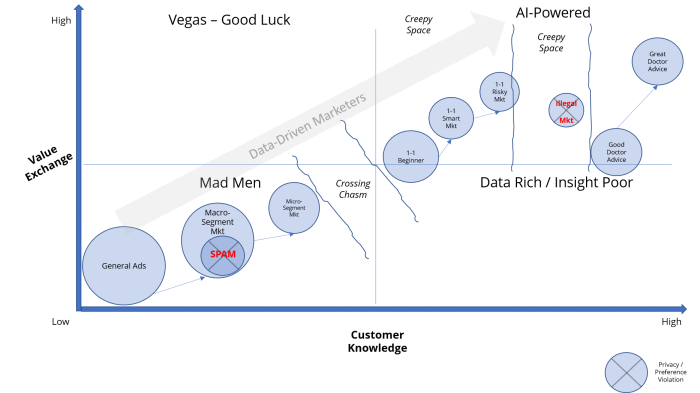
Figure 1: Evolution of Data-Driven Marketing. (Source: vincejeffs.com )
Here’s the bottom line: if a given customers perception is it’s creepy, it’s creepy. And depending on who slaps that label on, and whether their rights that have been violated, firms may face legal battles, fines, and reputation damage leading to significant commercial impact. For instance, potential fines for GDPR privacy law violators can reach 4 percent of a firm’s revenue (up to a maximum of €20 million).
And none of that is music to a businessperson’s ear.
Creeping toward creepy
In 2014, Pinterest managed to spam a major segment of customers when they sent emails to unengaged women congratulating them on their upcoming weddings. And Shutterfly made an even bigger spam faux pas that same year, congratulating women on the birth of babies they didn’t have.
In Figure 1, these events fall into the SPAM circle because marketers placed people into the wrong macro segments, and the resulting emails were both irrelevant and hilariously erroneous. Clumsy customer experiences indeed, but not creepy-smart marketing.
Here are some other examples of Mad Men SPAM marketing:
- You market wedding offers after a wedding – low sensitivity
- You market wedding offers after a cancelled wedding – high sensitivity
On the other hand, the risk of being labeled a creepy marketer increases when knowledge of customers goes up, insights increase, yet marketers fail to understand an individual’s sensitivity to certain marketing actions.
For each marketing treatment, you need to determine if it will be creepy to everyone or only some:
Figure 2a: Creepy Meter detecting creepy treatments (Source: vincejeffs.com )
If it’s clearly creepy to everyone, during the pre-market approval process you should reject it. But, if its potentially cool to some, and creepy to others, then provided you can discriminate at runtime using eligibility rules, you can approve its use for those who will find it cool.
To do this, get a readout on consumers’ sensitivity to hyper-personalization. Build a model that learns this, and use this score to select, by individual, the levels of personalization they’re eligible to receive.
Figure 2b: The Creepy Sensitivity Index readout on each consumer (Source: vincejeffs.com )
Here are a few examples of events, corresponding covert marketing approaches, and creepy readings:
| Event | Covert Marketing (but not illegal) | Creepy Meter | Approve? |
| Hospital admittance / serious health issues detected | Mortuary makes discount offers | Extremely creepy | Reject |
| Conversation recorded (without clear permission to use for marketing) | Ads for products related to keywords in the conversation (e.g., pet toy video recently, which illustrates the point yet is likely a hoax) | Very creepy | Reject |
| Facial recognition or location detection | Upon a patron entering a branch or store, their profile & preferences are relayed to a salesperson | Borderline creepy | Conditional |
| Consumer traveling; recent activity and calendar scanned | Push notifications offering travel recommendations based on triangulating travel intent and destination | Borderline creepy | Conditional |
| Consumer browsing a web page with product offers | Website background, images, language, offers, and other page fragments hyper-personalized | Borderline creepy | Conditional |
Table 1: Examples of potentially creepy marketing
Leading-edge 1:1 marketers are constantly listening for keywords, tracking interaction device, time & location, codifying behavior, sensing mood, recording preferences, and using that knowledge to hyper-personalize with content variations in the millions. The risk, however, is meandering into that forbidden creepy zone (even if it’s legal), so discerning this by customer by treatment is vital.
Suggestions
As you move into deeper levels of hyper-personalization, do so deliberately and methodically, fully grasping the implications before rolling out. Consider taking this approach:
- Collect only data that matters to your ability to personalize specific experiences – that your customer will value. For example, if you sell insurance, you don’t need to understand pet preferences unless you’re selling pet insurance.
- Start with simple / minimal risk personalization strategies. These should easily pass the creepy test. For instance, if you can tune you web experience to shopper color preferences, do it. No one will find that creepy.
- Gradually apply regional and demographic personalization strategies.
- Use AI to crawl your products and content to extract taxonomies, attributes, cross-classifications, and descriptions. This will help better match customer intent and preferences to products that will match needs.
- Use AI to match the right products to clients (making relevant recommendations) and doing so in a personalized way that enhances their experience
- Use sampling to test hyper-personalization treatments, selecting a wide variety of customers. Essentially, you get a stratified sample of creepiness raters.
- In general, avoid even borderline covert marketing unless you have a firm handle on any backlash that might result if customers discover it. In a recent survey, most consumers (81%) think firms are obligated to disclose they’re using AI – and how they’re using it.[iv]
- Be sensitive to consumers’ preferences for public recognition. Some might love it if you greet them by first name and show appreciation for their loyalty in public. A few, however, may be mortified.
Hyper-personalization requires great data, great technology, and great sensitivity. With GDPR now in effect, most businesses are proactively disclosing their data collection practices and privacy policies. As consumers, we’re consenting to and accepting new privacy policies more than ever before, and in some cases, we’re even reading and understanding them. Less clear, however, is exactly how that data is used, combined with other data, and when it might show up as an insight, recommendation, or hyper-personalization – and again, which of us might be freaked out by this personalization.
AI is driving personalization to new levels. There’s no stopping that. It automatically figures out what works and what doesn’t. Techniques, such as Bayesian algorithms, quickly learn which offers work, when, and in which channels. Others, like collaborative filtering, find which products pair best, that in turn drives cross-sell and bundling strategies. Design of experiments and monitoring devices measure the impact and enable fine tuning.
What’s missing, however, are tools to sense consumers’ sensitivity to personalization, so overt practices are optimized with the right people, and so covert methods are prevented from ever reaching production, or if they are approved for use, are carefully applied.
The study shown in Figure 3 provided some proof that overt personalization pays off. Yet the very definition of overt blurs as AI improves, content becomes hyper-conditional, and levels of personalization get more complex. Thus, you’ll need more sophisticated ways to gauge levels of personalization relative to creepiness, and the sensitivity levels of different people.
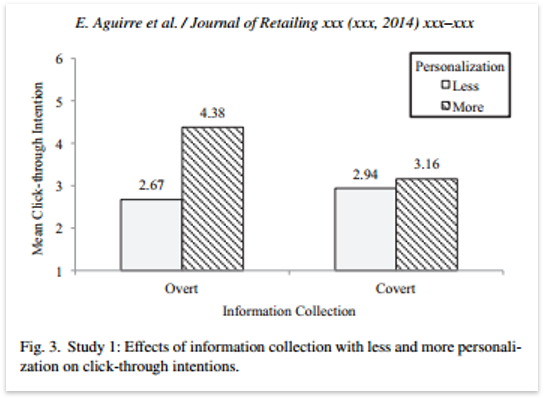
Figure 3: Overt vs covert personalization performance[v]
Conclusion
Great marketers push beyond perceived barriers by understanding customers, knowing products, and then elegantly combining creativity and technology to provide valuable recommendations and experiences to customers. Ironically, when done right in the eyes of the receiving consumer, they don’t appear to be selling anything; instead simply providing a service.
With website personalization, one-to-one content, natural language generation, image recognition, and countless other AI tools, businesses inexorably march toward hyper-personalization. Make sure you manage it, so you’re always cool and never creepy.
Endnotes:
[i] https://www1.pega.com/insights/resources/pegaworld-2018-pegas-ai-innovation-lab-sneak-peek-and-your-vote-counts-video, June 2018
[ii] http://pressroom.epsilon.com/new-epsilon-research-indicates-80-of-consumers-are-more-likely-to-make-a-purchase-when-brands-offer-personalized-experiences/, January 2018
[iii] https://www.forbes.com/sites/fionabriggs/2016/07/04/fingerprint-scanning-is-cool-but-facial-recognition-creepy-new-richrelevance-survey-shows/2/#493b953f3d68, July 2016
[iv] https://www.richrelevance.com/blog/2018/06/20/creepy-cool-2018-richrelevance-study-finds-80-consumers-demand-artificial-intelligence-ai-transparency/, June 2018
[v] https://www.sciencedirect.com/science/article/pii/S0022435914000669#abs0005, March 2015



Hi Vince: many years ago, I cold called a prospect for a software product I was selling. At the outset of the call, I used his first name. “Wait . . . have we spoken before?” he interrupted. I answered him honestly, saying that this was the first time we had talked. “How dare you use my first name . . . !” he yelled, adding some other choice words I won’t repeat here, before he quickly hung up on me. Perhaps he was having a bad day. But that’s not relevant here. I had usurped my prospect’s permission to use his first name, and assumed his trust – however slight. That doesn’t matter to everyone, but it clearly mattered to him. I never forgot the lesson.
Creepy is in the eye of the beholder, and I’m not sure if algorithmic analysis can reliably determine degrees of creepy. That means as business developers, we must use good old discretion, intuition, and empathy. We must navigate a mine field of customer sensitivities, both hidden and unhidden. And we can never assume that the magnitude of the reactions will be proportional to our ‘customer touches.’ That defies our pell mell embrace of all-things-AI, but this is a prominent example where human capability dominates.
Personalization has another drawback: for consumers, it represents a power imbalance. While it’s flattering for a website to “know” us when we log in, it’s also disconcerting to realize that it’s the vendor – not me – who has information hegemony. Even now, it gives me the jitters to think about it.
Back to my cold call debacle. My mistake was not in using my prospect’s first name, it was my timing for doing so. Had I waited until we had at least met in person, or until I asked permission to call him Jim or Steve or Mike or Wayne or whatever, maybe I could have eventually counted him among my customers. This idea can be extrapolated to personalization. I don’t mind Amazon “knowing me” because I’ve established a long buying relationship with the company. But it’s uncomfortable to have a website I have visited for the first time push content that makes it clear they possess similar insights.
Hi – may I call you Andrew? 🙂 Thanks for taking the time to share your story and comment. A prime story that I believe sets off this debate at the absolutely right point – at the very beginning of a relationship (1st touch) where it seems you knew very little about this person besides his name – with the question being how much do you personalize covertly and / or overtly (your example was covert to me, because you hadn’t asked permission or earned the right).
So you did make a pretty critical covert personalization decision with that call (that perhaps you were using up to that point with all of your other prospects without the same reaction). That is, to greet him with FIRST_NAME vs Mr LAST_NAME without permission to call him by first name (As I quipped above, when we’re trying to be polite in human to human interactions we still actually ask (usually not until we’ve talked to someone for a while, “May I call you FIRST_NAME ?”. Immediately addressing someone by first name is kind of the equivalent of walking up to a stranger in a French speaking country and addressing them using “Tu” vs “Vous.” I too, however, would have been surprised by his level of sensitivity.
Yet with that interaction, you certainly learned something about him (although not the painful lesson we want to repeat) and perhaps others like him; and you got his rating on that particular treatment. Clearly his creepy sensitivity index went from “unknown” to deep-red creepy with one treatment, and his rating on that treatment was a bright red CREEPY. As sales & marketing pros, I believe some of the keys are (which I tried to lay out) is that we need to approach this methodically and progressively, and be testing and learning at a 1:1 level as we go.
Thanks again for responding. Love the discourse. Best, Vince
The State of California — home to some of the tech giants that have abused privacy — just passed a law to give consumers more control. From http://money.cnn.com/2018/06/28/technology/california-consumer-privacy-act/index.html:
>>The law, which takes effect in 2020, gives consumers sweeping control over their personal data. It grants them the right to know what information companies like Facebook and Google are collecting, why they are collecting it, and who they are sharing it with. Consumers will have the option of barring tech companies from selling their data, and children under 16 must opt into allowing them to even collect their information at all.
>>
Also, “the law allows companies to charge higher prices to consumers who opt out of having their data sold.”
Some privacy advocates think this is a bridge too far (privacy is a right) but I think this will draw attention to the fact that nothing is free. Some sites already charge a fee to suppress ads which of course help generate the revenue necessary to pay for the content people are reading.
Personally I think most consumers will still choose the “free” option in return for sharing data (now more open and transparent thanks to GDPR), but it should be a choice.
The new law goes into effect in 2020, giving everyone time to lobby for improvements.
Andy, human-based personalization isn’t perfect, so we shouldn’t expect tech (by AI or whatever) to be perfect either.
But technology can and is being deployed to assess customer engagement with a brand, including sentiment, interests, and much more. Would you have us all go back to the world where we’re all treated exactly the same because AI may screw up occasionally? That’s not a standard you’d apply to humans.
Just as cars can learn to avoid most accidents, based in part on the experience of *having* accidents, machine learning can be used to help companies make smarter decisions about what is creepy or not. A simple example is a feedback loop with a consumer that approves or rejects a personalized message. That’s a learning loop just like your customer feedback on your failure to personalize correctly. You learned, why can’t a computer?
You see a form of this with Google ads today. Click on the top right triangle icon (Ad Choices) and you’ll see something like this:
>>
This ad is based on:
Websites you’ve visited
The information on the website you were viewing
The time of day or your general location (like your country or city)
>>
Followed by options to control ad settings, report bad sites, and more.
Online retailers should be more explicit about why they are showing certain content, offers, etc. and give consumers the opportunity to turn it off or make adjustments. For example, sometimes I’d like Netflix to stop recommending movies based on my history, because I’d like to explore different genres.
I’ve been following personalization for 20 years. Everyone says they want it, few brands can deliver. I think AI offers the only real hope to make personalization better and bring it within reach of more businesses.
I think Vince’s recommendation is sound: “we need to approach this methodically and progressively, and be testing and learning at a 1:1 level as we go.”
Thanks for sharing your insights Bob! (My meter says 99.9% sure you don’t mind me calling you Bob 🙂 )
I wasn’t aware of this new CA legislation, so I now plan to read it over (light night-time material I’m sure). As a long-time follower of this space also, it’s heating up, and well it should. Personally and professionally, I’ve always been a huge fan of permission-based marketing, as in the long run it benefits all the good actors. Consumers should know that nothing is really free (and here some level of protection and education is key), and businesses that properly balance their economics with true concern for the customer’s needs and best interests (I trust) will be the winners.
I know Customers are signaling that they want more personalized treatment from companies. In fact, a recent Accenture survey revealed that nearly 60% of respondents prefer real-time promotions and offers. That may seem like great news for marketers. But personalization strategies also come with risk but How To Fix The Personalization Paradox? Hyper Personalization Paradox will shut down it
I agree with Linh there are risks with increasing levels of personalization – I think in some cases those risk can even be quantified (e.g., the risk of an opt-out or a privacy law suit). That is why I believe it’s necessary to have the means to understand / predict, by individual and by treatment, whether the application of personalization will be viewed as valuable or not – and to learn from each experiment.