
In my last two columns “Starter Kit for Customer Experience Data Analytics” and “3 Tips for Customer Experience Analytics”, I introduced these four issues:
- “Where do I start?”
- “Do I need “Big Data” and, if so, what the heck is it?”
- “We have solid spreadsheet junkies but do I also need “data scientists” and, if so, where can I get them?”
- “How can I track progress?”
In my last column I posed it this way: “How can we hold onto our best performers? (So-called “best agents” and “best customers”)”
In this column I’ll build on these bases to focus on how using Big Data analytics to find and retain your best agents and your best supervisors can make a huge difference in your customer experience and in your employee experience. Next month I will address its codicil “Once I figure out who are my best agents, how can move my other agents to their performance levels?” Answering these questions will naturally lead to finding and retaining your best agents. And if it works for agents, why not also for supervisors?
Breaking these questions down, we will find that Big Data is the ideal tool to use: Not only can you use Big Data to “mash up different data sources, query them, test them, and produce a stronger solution than single-threaded approaches” (from my last column), but you can also use Big Data’s multivariate modeling to determine key drivers and to calculate a large series of “What if?” scenarios, and then test those models over time to determine the best fit.
Now let’s review briefly limitations using current approaches that we will task Big Data to address:
Limitations calculating “best agents”
Most organizations that I’ve seen over the past 22 years use stack ranking to portray best agents, usually a single metric such as productivity (AHT, typically) with the assumption that lower AHT is better or QA scores. Many others are moving away from AHT or internally generated QA scores, preferring to use FCR or post-interaction c-sat results. Some have toyed with a weighted average approach, for example 50% for FCR + 30% for attendance + 20% for QA.
All of these approaches assume that all agents are able to perform equally, despite overwhelming evidence that new agents are less capable but eager to improve, while experienced agents might plateau or not pursue new tools to improve their performance.
Limitations calculating “best supervisors”
Some organizations schedule their supervisors for the same shifts as their agents in a true team, but most randomly assign supervisors to a virtual or quasi-team of agents working roughly at the same time as the supervisor. In the true team you can roll up agents’ performance to present a scorecard for supervisors, but in the quasi-team it’s very hard to determine who’s the best supervisor.
Limitations determining retention plans or improvement paths
Best agent and best supervisor calculations are often batched on a monthly basis to guide coaching or scold for bad behavior, so they are not current enough to effect change; this means that agents and teams can persist delivering weak performance until spotted, and then it will still be hard to determine what to address to improve that performance – Carrots? Sticks? Closer scrutiny and double jacking? Remedial training?
Other limitations determining retention plans or improvement paths include not being to associate case and effect (e.g., which carrots matter to which agents?); biases from most recent observations rather than solid trended data; and treating all agents and supervisors the same, partly since it’s easier then segmenting them into groups.
There are two different approaches that confront these limitations to take advantage of the power of Big Data analytics.
First new approach
Based on the research into companies that consistently deliver great customer experiences, my co-author David Jaffe and I discovered that these “Me2B Leaders”1 considered their employees as essential to delight their customers. They told us that they wanted to deliver to their agents and managers the same 7 Needs and 39 Sub-Needs that we portrayed for customers, e.g. “You value my potential” and “You don’t tar me with the same brush”. This leads us to the first new approach, a truly individualized agent performance management program and an individualized supervisor performance management program – Not averages or “all the same,” but recognizing that each of your staff can excel at difference levels.
Second new approach
I’ve been a fan of balanced scorecards since my years with McKinsey & Company in the 1980s, more so when we consider the opposing factors that challenge our agents and supervisors. While companies say that AHT and productivity don’t matter any more, and that it’s now all about FCR or c-sat, it’s tantalizing to show AHT and encourage speed while agents are toiling to deliver higher quality. This leads to the second new approach, an X-Y matrix that juxtaposes efficiency vs. effectiveness, with each axis produced using a weighted average of 2-5 variables that also take into account individual differences from the 1st new approach.
Next we’ll explore how this works in practice using Big Data to figure out “Who are my best agents and how can I find more new hires like them?” Let’s start with defining the variables that belong on both axes, and then adjust for individual differences. Then we’ll finish with how to find more agents that are like the best agents.
Variables on each axis
On the X-axis for effectiveness we might want to consider these key metrics, weighted:
- Post-interaction c-sat scores, focusing on the top box (if you offer 5 levels).
- Post-interaction questions about NPS or customer effort (CES).
- Internal QA scores, focusing on the elements that your customers deem most important.
- Subsequent purchases by these serviced customers versus a control group.
- FCR or its cousin First Point Resolution (FPR, keeping the customer at the first point of contact with no transfers).
- Inferred c-sat, NPS, or CES using a range of customer journey analytics.
The first three metrics suffer from low response rates and skewed scores (high or low), but can provide good value with verbatim comments that can be mined and included in the X-axis. The last three metrics are harder to obtain but potentially provide greater value. All five (and the data mining) are perfect for Big Data’s ability to access disparate data sources such as CRM, c-sat, and HR systems.
On the Y-axis for efficiency we might want to include these key metrics, also weighted:
- Sales per hour.
- Contacts handled per hour.
- Conversion or retention rates.
- Attendance (since if you don’t show up, you can’t support!).
Adjusting for individual differences
As mentioned earlier, not all agents or supervisors “are created equal” so it’s essential to recognize and report individual differences. What works well is what I’ve been calling Dynamic Individual Metrics or DIM, e.g., Dynamic Individual Handle Time or DIHT2. DIM adjusts targets and displays relative performance based on tenure, issue degree of difficulty, customer degree of difficulty, and other factors that Big Data can collect and mash up. Using DIM a new agent’s target for FCR for simple issues might be the same as an experienced agent’s FCR for tough issues, easing the growth path for all agents.
How to find more agents that are like the best agents
Now that we’ve collected the metrics on both axes, adjusted targets and results using DIM, it’s time to plot all agents on the X-Y axis as this example shows:
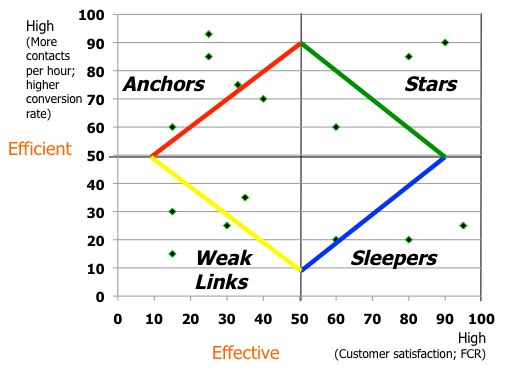
The Stars or “best agents” in the upper right corner somehow are able to achieve both high levels of efficiency and effectiveness, so that’s where we start: You can collect and model using Big Data potential drivers such as prior jobs, hiring and initial training class, distance from work or commute time, number of supervisors (and which ones), and more. By running multiple models and finding best fit, you are able to learn what determines a “best agent” and how to re-tool your hiring profile, trainer profile, supervisory assignments, and the other key drivers.
Time then to run the same models for all other agents, revealing key differences that begin to explain their weaker performance, and that’s what I’ll address next month.
Notes
1
Your Customer Rules! Delivering the Me2B Experiences That Today’s Customers Demand
, Bill Price & David Jaffe (Wiley 2015). Based on original research into 12 recognized CX leaders there are the 7 Customer Needs that produce
a winning “Me2B” culture, with a total of 39 sub-needs:
1. “You know me, you remember me”
2. “You give me choices”
3. “You make it easy for me”
4. “You value me”
5. “You trust me”
6. “You surprise me with stuff that I can’t imagine”
2 The Best Service is No Service: Liberating Your Customers From Customer Service, Keep Them Happy, and Control Costs , Bill Price & David Jaffe (Wiley 2008).


