
 Source: Shutterstock.
Source: Shutterstock.
Let’s bring some clarity to the messy subject of Advanced Text Analytics, the way it’s pitched by various vendors and data scientists. This is the 3rd of a series of 5 posts, where I explain what’s popular and what’s possible.
If you haven’t read my earlier posts here are the links to:
- Approach 1. Word Spotting, which you can build in 10 min or less
- Approach 2. Manual rules, which is what most major players offer
As you can guess, both of these approaches have shortcomings, but most importantly, they aren’t advanced, because a person has to painstakingly tell the algorithm what to look for.
Today, we’ll be looking at Text Categorization, the first of the three approaches that are actually automated and use algorithms.
What is text categorization?
This approach is powered by machine learning. The basic idea is that a machine learning algorithm (there are many) analyzes previously manually categorized examples (the training data) and figures out the rules for categorizing new examples. It’s a supervised approach.
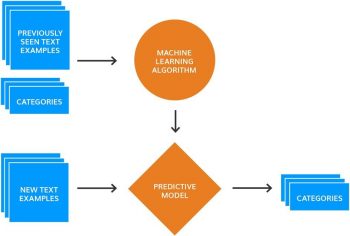 Source: Thematic.
Source: Thematic.
The beauty of text categorization is that you simply need to provide examples, no manual creation of patterns or rules needed, unlike in the two previous approaches.
Another advantage of text categorization is that, theoretically, it should be able to capture the relative importance of a word occurrence in text. Let’s revisit the example from earlier posts. A customer may be explaining the situation that leads to an issue: “My credit card got declined and the cashier was super helpful, waiting patiently while I searched for cash in my bag.” This comment is not about credit cards or cash, it’s about the behaviour of the staff. The theme “credit card” mentioned in the comment isn’t important, but “helpfulness” and “patience” is. A text categorization approach can capture it with the right training.
It all comes down seeing similar examples in the training data.
Near perfect accuracy… but only with the right training data
There are academic research papers that show that text categorization can achieve near perfect accuracy. Deep Learning algorithms are even more powerful than the old naïve ones (one older algorithm is actually called Naïve Bayes).
And yet, all researchers agree that the algorithm isn’t as important as the training data.
The quality and the amount of the training data is the deciding factor in how successful this approach is for dealing with feedback. So, how much is enough? Well, it depends on the number of categories and the algorithm used to create a categorization model.
The more categories you have and the more closely related they are, the more training data is needed to help the algorithm to differentiate between them.
Some of the newer Text Analytics startups that rely on text categorization provide tools that make it easy for people to train the algorithms, so that they get better over time. But do you have time to wait for the algorithm to get better, or do you need to act on customer feedback today?
Four issues with text categorization
Apart from needing to train the algorithm, here are four other problems with using text categorization for analyzing people’s feedback:
1. You won’t notice emerging themes
You will only learn insights about categories that you trained for and will miss the unknown unknowns. This is the same disadvantage as manual rules and word spotting has: The need to continuously monitor the incoming feedback for emerging themes, and mis-categorized items.
2. Lack of transparency
While the algorithm gets better over time, it is impossible to understand why it works the way it works and therefore easily tweak the results. Qualitative researchers have told me that the lack of transparency is the main reason why text categorization did not take off in their world. For example, if there is suddenly poor accuracy on differentiating between two themes “wait time to install fiber” and “wait time on the phone to setup fiber”, how much training data does one need to add, until the algorithm stops making these mistakes?
3. Preparing and managing training data is hard
The lack of training data is a real issue. It’s hard to start from scratch and most companies don’t have enough or accurate enough data to train the algorithms. In fact, companies always overestimate how much training data they have, which makes implementation fall below expectations. And finally, if you need to refine one specific category, you will need to re-label all of the data from scratch.
4. Re-training for each new dataset
Transferability can be really problematic! Imagine you have a working text categorization solution for one of your departments, e.g. support, and now want to analyse feedback that comes through customer surveys, like NPS or CSAT. Again, you would need to re-train the algorithm.
I just got of the phone with a subject matter expert on survey analysis, who told me this story: A team of data scientists spent many months and created a solution that she ultimately had to dismiss due to lack of accuracy. The company did not have time to wait for the algorithm to get better over time.
So, is there a perfect approach out there? Stay tuned for Part 4 and 5.
This post was first published here.


