
In this Big Data world, a major goal for businesses is to maximize the value of all their customer data. Most customer data, however, are housed in separate data silos. While each data silo contains important pieces of information about your customers, if you don’t connect those pieces across those different data silos, you’re only seeing parts of the entire customer puzzle.
The integration of these disparate customer data silos helps your analytics team to identify the interrelationships among the different pieces of customer information, including their purchasing behavior, values, interests, attitudes about your brand, interactions with your brand and more. Integrating information/facts about your customers allows you to gain an understanding about how all the variables work together (i.e., are related to each other), driving deeper customer insight about why customers churn, recommend you and buy more from you.
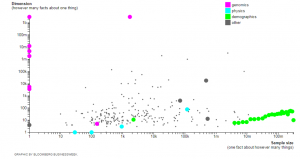
You can describe a data set (silo) along two dimensions: 1) the sample size (number of entities in the data set) and 2) the number of variables (number of facts about each entity). Figure 1 includes a good illustration of different data sets and how they fall along these two size-related dimensions (For the interested reader, check out the figure in this interactive graphic).
Dimension vs Sample Size
For data sets in the upper left area of Figure 1, we know many facts about a few people. Data sets about the human genome (see human genome) are good examples of these types of data sets. For data sets in the lower right area, we know a few facts about a lot of people (e.g., US Census). Data silos in business are good examples of these types of data sets.
Mapping and understanding of all the genes of humans allows for deep personalization in healthcare through focused drug treatments (i.e., pharmacogenomics) and risk assessment of genetic disorders (e.g., genetic counseling, genetic testing). The human genome project allows healthcare professionals to look beyond the “one size fits all” approach to a more tailored approach of addressing healthcare needs of a particular patient.
Siloed data sets prevent business leaders from gaining a complete understanding of their customers. In this scenario, analytics can only be conducted within one data silo at a time, restricting the set of information (i.e., variables) that can be used to describe a given phenomenon; your analytic models are likely underspecified (not using the complete set of useful predictors), decreasing your model’s predictive power / increasing your model’s error. The bottom line is that you are not able to make the best prediction about your customers because you don’t have all the necessary information about them.
In my next post, I will extend the concept of the human genome project to the world of customer experience management to illustrate how businesses can use the power of datq integration to connect their data silos and apply machine learning capabilities for deeper customer understanding.


