
Online shopping has grown by leaps and bounds in the last few years. The number of e-commerce buyers is estimated to reach a whopping 2.14 billion by 2021. With e-commerce sites competing for buyer’s attention, a tool that comes in handy in attracting customers and ensuring repeat business is the product recommendation engine.
And if set up and configured properly, it can significantly boost revenues, CTRs, conversions, and other important metrics. Moreover, product recommendation can have positive effects on the user experience as well, which translates into metrics that are harder to measure but are nonetheless of much importance to online businesses, such as customer satisfaction and retention.
All this is only possible with a product recommendations engine. Recommendation engines basically are data filtering tools that make use of algorithms and data to recommend the most relevant items to a particular user. Or in simple terms, they are nothing but an automated form of a “shop counter guy”. You ask him for a product. Not only he shows that product, but also the related ones which you could buy. They are well trained in cross-selling and upselling.
With the growing amount of information on the internet and with a significant rise in the number of users, it is becoming important for companies to search, map and provide them with the relevant chunk of information according to their preferences and tastes.
Let’s consider an example to better understand the concept of a product recommendation engine. If I am not wrong, almost all of you must have used Amazon for shopping. And just so you know, 35% of Amazon.com’s revenue is generated by its product recommendation engine. So what’s their strategy?
Amazon uses recommendations as a targeted marketing tool in both email campaigns and on most of its websites pages. Amazon will recommend many products from different categories based on what you are browsing and pull those products in front of you which you are likely to buy. Like the ‘frequently bought together’ option that comes at the bottom of the product page to lure you into buying the combo. This recommendation has one main goal: increase average order value i.e., to up-sell and cross-sell customers by providing product suggestions based on the items in their shopping cart or below products they’re currently looking at on-site.
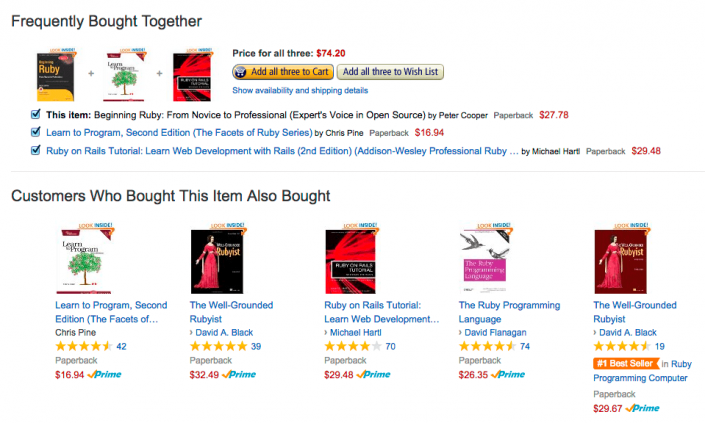
Reference: Amazon
Amazon wants to make you buy a package rather than one product. Say you bought a phone, it will then recommend you to buy a case or a screen protector. It will further use the recommendations from the engine to email and keep you engaged with the current trend of the product/ category.
WHAT ARE THE DIFFERENT TYPES OF RECOMMENDATIONS?
There are basically three important types of recommendation engines:
- Collaborative filtering
- Content-Based Filtering
- Hybrid Recommendation Systems
Collaborative filtering:
This filtering method is usually based on collecting and analyzing information on user’s behaviors, their activities or preferences and predicting what they will like based on the similarity with other users. A key advantage of the collaborative filtering approach is that it does not rely on machine analyzable content and thus it is capable of accurately recommending complex items such as movies without requiring an “understanding” of the item itself.Collaborative filtering is based on the assumption that people who agreed in the past will agree in the future, and that they will like similar kinds of items as they liked in the past. For example, if a person A likes item 1, 2, 3 and B like 2,3,4 then they have similar interests and A should like item 4 and B should like item 1.
Further, there are several types of collaborative filtering algorithms:
- User-User Collaborative filtering: Here, we try to search for lookalike customers and offer products based on what his/her lookalike has chosen. This algorithm is very effective but takes a lot of time and resources. This type of filtering requires computing every customer pair information which takes time. So, for big base platforms, this algorithm is hard to put in place.
- Item-Item Collaborative filtering: It is very similar to the previous algorithm, but instead of finding a customer look alike, we try finding item look alike. Once we have item look alike matrix, we can easily recommend alike items to a customer who has purchased any item from the store. This algorithm requires far fewer resources than user-user collaborative filtering. Hence, for a new customer, the algorithm takes far lesser time than user-user collaborate as we don’t need all similarity scores between customers. Amazon uses this approach in its product recommendation engine to show related products which boost sales.
- Other simpler algorithms: There are other approaches like market basket analysis, which generally do not have high predictive power than the algorithms described above.
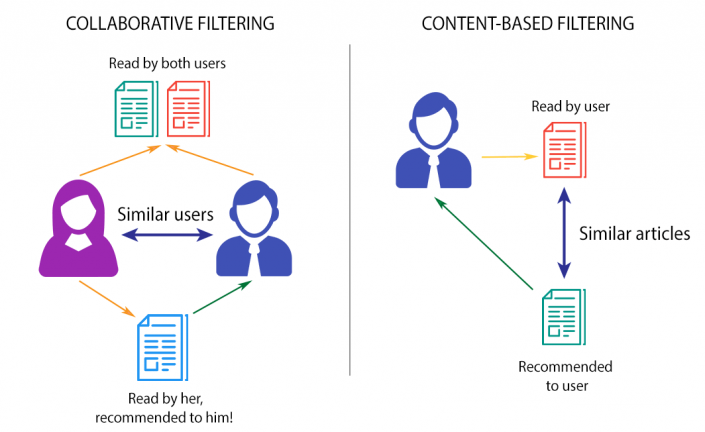
Content-based filtering:
These filtering methods are based on the description of an item and a profile of the user’s preferred choices. In a content-based recommendation system, keywords are used to describe the items; besides, a user profile is built to state the type of item this user likes. In other words, the algorithms try to recommend products which are similar to the ones that a user has liked in the past.
The idea of content-based filtering is that if you like an item you will also like a ‘similar’ item. For example, when we are recommending the same kind of item like a movie or song recommendation. This approach has its roots in information retrieval and information filtering research.
Hybrid Recommendation systems:
Combining collaborative and content-based recommendations can be more effective. Hybrid approaches can be implemented by making content-based and collaborative-based predictions separately and then combining them. Further, by adding content-based capabilities to a collaborative-based approach and vice versa; or by unifying the approaches into one model.
Several studies focused on comparing the performance of the hybrid with the pure collaborative and content-based methods and demonstrate that hybrid methods can provide more accurate recommendations than pure approaches. Such methods can be used to overcome the common problems in recommendation systems such as cold start and the data paucity problem.
Netflix is a good example of the use of hybrid recommender systems. The website makes recommendations by comparing the watching and searching habits of similar users (i.e., collaborative filtering) as well as by offering movies that share characteristics with films that a user has rated highly (content-based filtering).
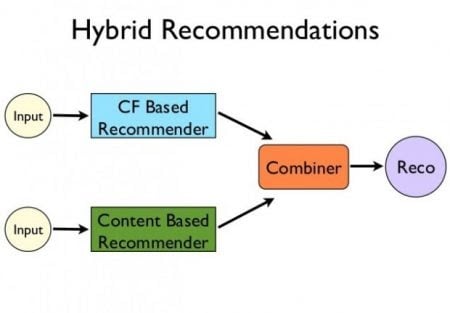
Reference: http://dataconomy.com/2015/03/an-introduction-to-recommendation-engines/
HOW DOES A PRODUCT RECOMMENDATION ENGINE WORK?
According to the article Using Machine Learning on Compute Engine to Make Product Recommendations, a typical product recommendation engine processes data through the following four phases namely collection, storing, analyzing and filtering.
Collection of data:
The first step in creating a product recommendation engine is gathering data. Data can be either explicit or implicit data. Explicit data would consist of data inputted by users such as ratings and comments on products. And implicit data would be the order history/return history, Cart events, Pageviews, Click thru and search log. This data set will be created for every user visiting the site.
Behavior data is easy to collect because you can keep a log of user activities on your site. Collecting this data is also straightforward because it doesn’t need any extra action from the user; they’re already using the application. The downside of this approach is that it’s harder to analyze the data. For example, filtering the needful logs from the less needful ones can be cumbersome.
Since each user is bound to have different likes or dislikes about a product, their data sets will be distinct. Over time as you ‘feed’ the engine more data, it gets smarter and smarter with its recommendations so that your email subscribers and customers are more likely to engage, click and buy. Just like how Amazon’s product recommendation engine works with the ‘Frequently bought together’ and ‘Recommended for you’ tab.
Storing the data:
The more data you can make available to your algorithms, better the recommendations will be. This means that any recommendations project can quickly turn into a big data project.
The type of data that you use to create recommendations can help you decide the type of storage you should use. You could choose to use a NoSQL database, a standard SQL database, or even some kind of object storage. Each of these options is viable depending on whether you’re capturing user input or behavior and on factors such as ease of implementation, the amount of data that the storage can manage, integration with the rest of the environment, and portability.
When saving user ratings or comments, a scalable and managed database minimizes the number of tasks required and helps to focus on the recommendation. Cloud SQL fulfills both of these needs and also makes it easy to load the data directly from Spark.
Analyzing the data:
How do we find items that have similar user engagement data? In order to do so, we filter the data by using different analysis methods. If you want to provide immediate recommendations to the user as they are viewing the product then you will need a more nimble type of analysis. Some of the ways in which we can analyze the data are:
- Real-time systems can process data as it’s created. This type of system usually involves tools that can process and analyze streams of events. A real-time system would be required to give in-the-moment recommendations.
- Batch analysis demands you to process the data periodically. This approach implies that enough data needs to be created in order to make the analysis relevant, such as daily sales volume. A batch system might work fine to send an e-mail at a later date.
- Near-real-time analysis lets you gather data quickly so you can refresh the analytics every few minutes or seconds. A near-real-time system works best for providing recommendations during the same browsing session.

Filtering the data:
Next step would be to filter the data to get the relevant data necessary to provide recommendations to the user. We have to choose an algorithm that would better suit the recommendation engine from the list of algorithms explained above. Like
- Content-based: A popular, recommended product has similar characteristics to what a user views or likes.
- Cluster: Recommended products go well together, no matter what other users have done.
- Collaborative: Other users, who like the same products as another user views or likes, will also like a recommended product.
Collaborative filtering enables you to make product attributes theoretical and make predictions based on user tastes. The output of this filtering is based on the assumption that two users who liked the same products in the past will probably like the same ones now or in the future
You can represent data about ratings or interactions as a set of matrices, with products and users as dimensions. Assume that the following two matrices are similar, but then we deduct the second from the first by replacing existing ratings with the number one and missing ratings by the number zero. The resulting matrix is a truth table where a number one represents an interaction by users with a product.
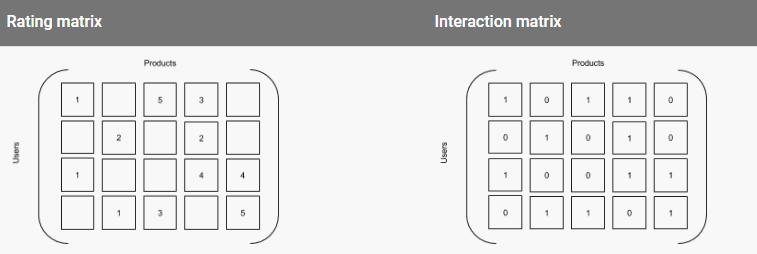
Ref: https://cloud.google.com/solutions/recommendations-using-machine-learning-on-compute-engine#storing_the_data
We use K-Nearest algorithm, Jaccard’s coefficient, Dijkstra’s algorithm, cosine similarity to better relate the data sets of people for recommending based on the rating or product.
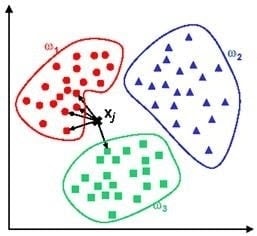
The above graph shows how a k-nearest algorithm’s cluster filtering works.
Then finally, the result obtained after filtering and using the algorithm, recommendations are given to the user based on the timeliness of the type of recommendation. Whether real time recommendation or sending an email later after some time.
HOW YOUR ORGANIZATION CAN IMPLEMENT PRODUCT RECOMMENDATION ENGINE?
Since a product recommendation engine mainly runs on data. Your company may not have the storage capacity to store this enormous amount of data from visitors on your site. You can use online frameworks like Hadoop, Spark which allows you to store data in multiple devices to reduce dependability on one machine. Hadoop uses HDFS to split files into large blocks and distributes them across nodes in a cluster. This allows the dataset to be processed faster and more efficiently than it would be in a more conventional supercomputer architecture that relies on a parallel file system where computation and data are distributed via high-speed networking.
Finally, we process big data sets using the MapReduce programming model. With this, we can run the algorithm in the distributed file system at the same time and choose the most similar cluster. Thus any organization can develop its own product recommendation engine architecture using open source tools and we can help them in implementing the engine using our technical expertise.
BENEFITS OF A PRODUCT RECOMMENDATION ENGINE
You do not need market research to find out whether a customer is willing to purchase at a shop where they’re getting maximum help in scouting the right product. They’re also much more likely to return to such a shop in the future. To get an idea about the business value of recommender systems: A few months ago, Netflix estimated, that its recommendation engine is worth a yearly $1billion.
There are 2 major benefits of using a product recommendation engine – revenue and customer satisfaction. Here we know more about those 2 and some more:
Revenue – With years of research, experiments and execution primarily driven by Amazon, not only is there less of a learning curve for online customers today. Many different algorithms have also been explored, executed, and proven to drive high conversion rate vs. non-personalized product recommendations.
Customer Satisfaction – Many a time customers tend to look at their product recommendation from their last browsing. Mainly because they think they will find better opportunities for good products. When they leave the site and come back later; it would help if their browsing data from the previous session was available. This could further help and guide their e-Commerce activities, similar to experienced assistants at Brick and Mortar stores. This type of customer satisfaction leads to customer retention.
Personalization – We often take recommendations from friends and family because we trust their opinion. They know what we like better than anyone else. This is the sole reason they are good at recommending things and is what recommendation systems try to model. You can use the data accumulated indirectly to improve your website’s overall services and ensure that they are suitable according to a user’s preferences. In return, the user will be placed in a better mood to purchase your products or services.
Discovery – For example, the “Genius Recommendations” feature of iTunes, “Frequently Bought Together” of Amazon.com makes surprising recommendations which are similar to what we already like. People generally like to be suggested things which they would like, and when they use a site which can relate to his/her choices extremely perfectly then he/she is bound to visit that site again.
Provide Reports – Is an integral part of a personalization system. Giving the client accurate and up to the minute reporting allows him to make solid decisions about his site and the direction of a campaign. Based on these reports clients can generate offers for slow moving products in order to create a drive in sales.
CONCLUSION
Sure, making an online sale is satisfying, but what if you were able to make a little more? An e-commerce organization can use the different types of filtering (Collaborative, content-based, and hybrid) to make an effective product recommendation engine.
The first step to having great product recommendations for your customers is really just having the courage to dive into better conversions. And remember – the only way to truly engage with customers is to communicate with each as an individual.
There is a more advanced and non-traditional method to power your recommendation process. These techniques namely deep learning, social learning, and tensor factorization are based on machine learning services and neural networks. Such cognitive computing methods can take the quality of your recommenders to the next level.
Our experts at Maruti Techlabs have designed systems that learn, interact and perform complex tasks without human intervention. We enable rapid decision making and process automation for your business using computational intelligence and deep learning frameworks. If you too want to create a much better process for customer satisfaction and retention, please get in touch with us here.


