
This was a rough week for the folks at Marketo. If you hadn’t heard, they somehow let their marketo.com domain expire. This brought down their website, customer consoles, and — most unfortunately — things like Marketo tracking scripts, landing pages, and web forms that their customers were relying on for their customer-facing web experiences. Due to the time delays involved in DNS, it took a couple of days to resolve.
Ouch.
One interesting part of the story is the good samaritan who leapt into action and paid their domain renewal fee. But there were other aspects of how this played out that I’d like to call attention to.
#1. Fact: complex systems suffer black swan events.
Large-scale systems with a massive number of moving parts and entangled interdependencies are going to suffer from “black swan” events — something terrible that happens unexpectedly, often triggered by something relatively minor, but with disastrous ripple effects.
It’s impossible to fully protect yourself against black swan events.
Sure, Marketo should have had better mechanisms in place to make sure their domain didn’t expire. In retrospect, that’s easy to point out.
But there’s an infinite number of other ways a black swan could occur. And it’s certainly not limited to Marketo. For instance, Amazon arguably operates one of the most impressive large-scale systems in the world — but earlier this year, they too suffered a major outage due to a small human error. Last year, a technical malfunction at UltraDNS brought down a ton of websites, including Netflix, for 90 minutes.
I’m not saying any of these outages should be waved away or that every effort shouldn’t be made to prevent them. Or that customers shouldn’t evaluate vendors for these kinds of risks (or, for that matter, consider contingencies on every business-critical software or service they rely on).
But these things will happen from time-to-time even with the most fastidious systems management teams. And I think Marketo responded well to the crisis, with their CEO directly taking responsibility over email and Twitter.
#2. People in glass houses: all of martech is a complex system.
Some of Marketo’s competitors took this opportunity to take jabs at them. To be expected, I suppose. It’s a rough-and-tumble market. When a rival stumbles, the wolves rush in.
But overplaying that hand is a bit cavalier. There isn’t a single company in martech that isn’t at risk of black swan events from their own complex constructions built on complex foundations operating in a complex environment. Public taunts could easily come back to haunt them.
In contrast, one of the classier responses I saw was from Tim Merrill, a product designer at HubSpot, who tweeted this:
“There but by the grace of god.” Humility is an admirable trait, but it also signals respect for the underlying complexity of this stuff. I’d choose that over bravado.
#3. Marketo’s ecosystem helped mitigate the consequences.
But the most interesting aspect of this Marketo outage — at least to me — was the dynamics that their ecosystem played in mitigating the consequences of this catastrophe for many of their customers. (Martech ecosystems FTW!)
Marketo customers who were using other software for front-end user experiences, possibly combined with iPaaS software (which we were just talking about earlier this week) were more robust to this failure.
Uberflip was bragging about this on Twitter. Their software collects leads, which then get passed into Marketo using APIs behind the scenes. But if for whatever reason Marketo isn’t accessible at a given moment — this time it was Marketo’s fault, but the same thing could happen if there’s an interruption anywhere between the two systems in the wild and woolly Internet — their software waits to retry sending the lead data at a later time.

Actually, the same thing was true for many of our customers at ion interactive (disclaimer: I am the co-founder and CTO), who integrate our interactive content software with Marketo. Our software collected the leads, and when Marketo’s APIs stopped responding, it kept retrying them in a queue. As soon as Marketo was reachable again, the leads went through.
For companies using an iPaaS solution where the data being routed between systems is maintained independently (e.g., as with a CDP), the same was true. They sync’d up with Marketo when it was back online. This is eventual consistency within a martech stack.
Which raises an interesting question: is a multi-vendor marketing stack always more robust?
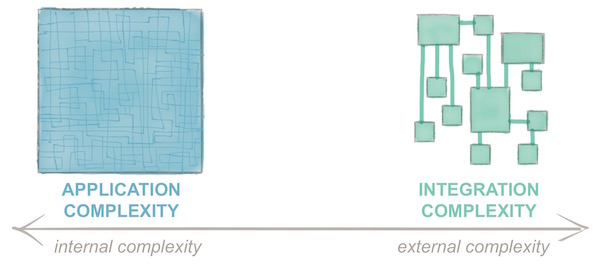
Well, yes and no. In some ways, it’s more robust because you aren’t reliant on a single vendor for your entire marketing operations and because the individual components in your stack are “simpler” (relatively speaking) and have less internal complexity.
For the Marketo outage, a little integration complexity saved some people’s bacon.
On the other hand, the more vendors you have, the more likely it is that any one of them might suffer a black swan event at some point. And you trade the internal complexity of a monolithic application for the external complexity of integrating those different components. I discussed this trade off in 5 Disruptions to Marketing, Part 2: Microservices & APIs.
Overall, I’d say the optionality of a well-architected multi-vendor marketing stack is probably slightly more robust in the sense that it diffuses vendor risk beyond just the concern of short-term service interruptions. (Also, not for nothing, marketers generally prefer best-of-breed stacks for the marketing work they do.)
But even if multi-vendor stacks aren’t markedly more robust, the counterpoint I’d make is that a single-vendor stack isn’t necessarily more robust either.
The Marketo outage this week should serve as a poignant reminder of that.


